What is Self-Attention?
Self-attention lets each token in a sequence look at every other token and decide
how much it should "attend" to them when building its own representation.
Unlike RNNs, this happens in parallel — making Transformers highly efficient on GPUs.
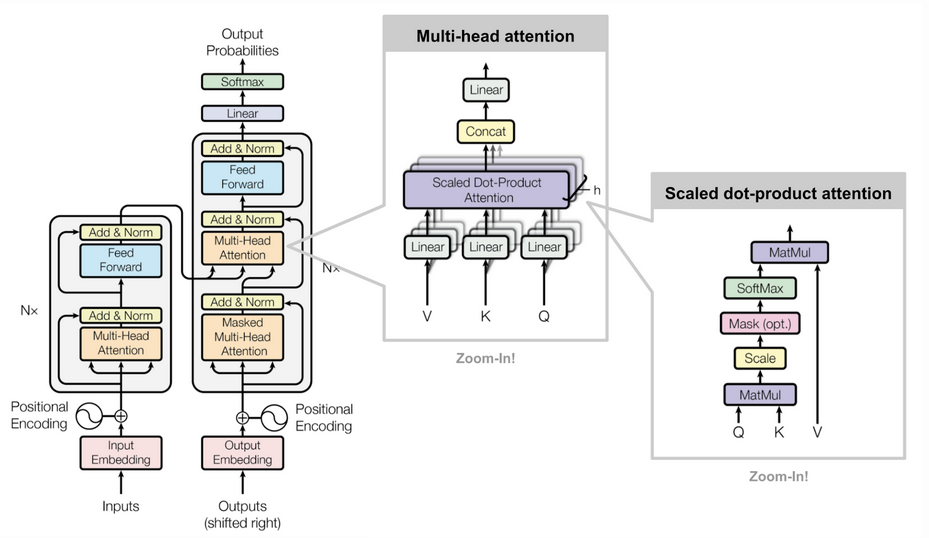
The Q, K, V Intuition
Every token produces three vectors:
- Query (Q) — "What am I looking for?"
- Key (K) — "What do I contain?"
- Value (V) — "What do I actually pass along?"
Attention is computed as:
Attention(Q, K, V) = softmax( QKᵀ / √dₖ ) · VThe dot product QKᵀ scores how relevant each key is to the current query.
Dividing by √dₖ keeps gradients stable when the embedding dimension is large.
PyTorch Implementation
import torch
import torch.nn.functional as F
def self_attention(x, W_q, W_k, W_v):
Q = x @ W_q # (seq, d_model) → (seq, d_k)
K = x @ W_k
V = x @ W_v
d_k = Q.shape[-1]
scores = Q @ K.transpose(-2, -1) / d_k ** 0.5 # (seq, seq)
weights = F.softmax(scores, dim=-1)
return weights @ V # (seq, d_v)Multi-Head Attention
Running h attention heads in parallel and concatenating lets the model
attend to different representation subspaces simultaneously:
# Split d_model into h heads, run attention per head, concat + project
MultiHead(Q,K,V) = Concat(head_1, ..., head_h) · W_o
Why Does It Work?
Self-attention is permutation-equivariant — it has no built-in sense of order.
That is why Transformers add positional encodings before the attention layers.
But it means the model can capture long-range dependencies in a single pass,
something that takes many steps for RNNs.