In-Depth Look at the Multimodal Transformer for Unaligned Multimodal Language Sequences

Introduction
The paper “Multimodal Transformer for Unaligned Multimodal Language Sequences” introduces a powerful approach to tackle unaligned multimodal sequences by leveraging the Transformer architecture. This is crucial for tasks like video understanding, sentiment analysis, and language grounding where different modalities, such as text, speech, and visual data, are not synchronized in time. In this post, we’ll dive deep into the model architecture and explain how the Multimodal Transformer (MT) achieves its performance with detailed explanations and code snippets to bring the concept to life.
Key Challenges Addressed by the Model
Before we dig into the architecture, let’s review the challenges the Multimodal Transformer aims to solve:
- Unaligned Modalities: Different modalities (e.g., text and video) may not be temporally aligned.
- Asynchronous Timing: The duration and timing of different modality streams can vary significantly.
- Cross-Modal Dependencies: Capturing meaningful relationships between modalities, even when they are temporally misaligned.
Multimodal Transformer Architecture
The Multimodal Transformer (MT) is designed to handle input from multiple modalities and processes them simultaneously using a combination of self-attention and cross-modal attention mechanisms. The key components of the architecture are:
1. Feature Extraction
The first step is extracting features from each modality independently. These features are passed to modality-specific transformers for separate processing. Common feature extractors include:
- Text: Using pre-trained embeddings like BERT or Word2Vec.
- Audio: Using acoustic features like MFCC (Mel Frequency Cepstral Coefficients).
- Visual: Using CNN-based feature extractors for image or video frames.
For simplicity, here’s a basic Python pseudocode for feature extraction:
from transformers import BertModel
import librosa
import torch
import torchvision.models as models
# Text Feature Extraction
text_model = BertModel.from_pretrained('bert-base-uncased')
text_inputs = tokenizer("sample text", return_tensors='pt')
text_features = text_model(**text_inputs).last_hidden_state
# Audio Feature Extraction
audio, sr = librosa.load('audio_file.wav', sr=16000)
audio_features = librosa.feature.mfcc(audio, sr=sr)
# Visual Feature Extraction
cnn_model = models.resnet50(pretrained=True)
visual_input = torch.randn(1, 3, 224, 224) # Simulating an image
visual_features = cnn_model(visual_input)
Each extracted feature set is passed to its respective modality-specific encoder.
2. Modality-Specific Encoders
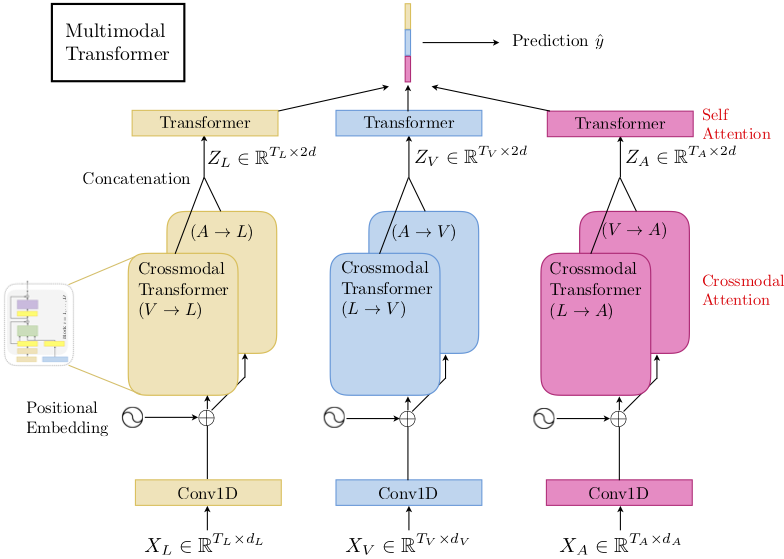
Each modality (text, audio, video) is processed through its own transformer encoder, which consists of multiple layers of self-attention and feed-forward networks. These encoders learn the intra-modality relationships. The transformer encoder follows the traditional architecture:
import torch.nn as nn
class TransformerEncoder(nn.Module):
def __init__(self, d_model, nhead, num_layers):
super(TransformerEncoder, self).__init__()
self.encoder_layers = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layers, num_layers=num_layers)
def forward(self, src):
output = self.transformer_encoder(src)
return output
# Example for Text
d_model = 512
nhead = 8
num_layers = 6
text_encoder = TransformerEncoder(d_model, nhead, num_layers)
text_encoded = text_encoder(text_features)
Each modality’s encoder operates independently, generating modality-specific hidden representations.
3. Cross-Modal Attention Mechanism
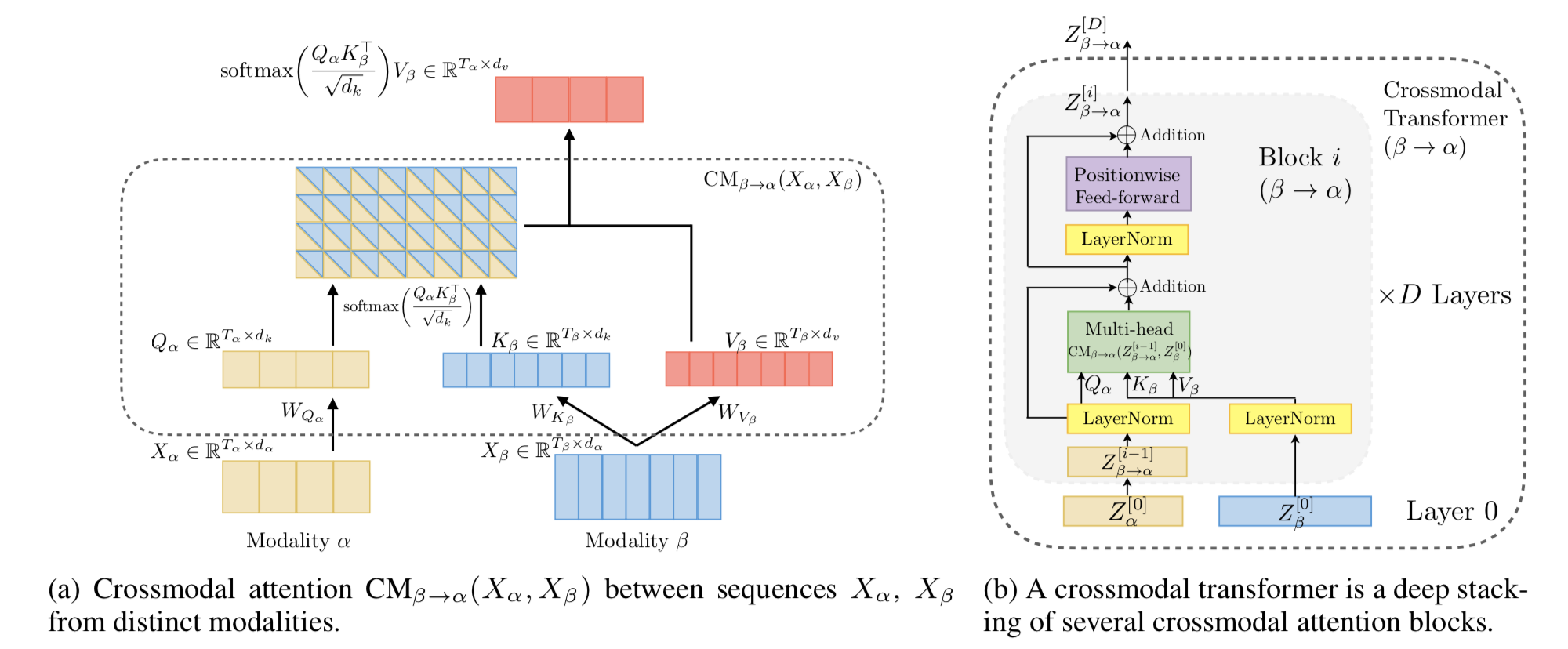
One of the most innovative parts of this model is the Cross-Modal Attention Mechanism, which allows different modalities to attend to each other. This mechanism is crucial for capturing relationships between text, audio, and visual streams, even when they are temporally misaligned.
Cross-modal attention works by learning relationships between the representations of different modalities. The model computes attention weights between all elements across modalities, allowing the information flow between asynchronous data streams.
Here’s a simplified code snippet demonstrating the cross-modal attention:
import torch
import torch.nn.functional as F
class CrossModalAttention(nn.Module):
def __init__(self, d_model):
super(CrossModalAttention, self).__init__()
self.query = nn.Linear(d_model, d_model)
self.key = nn.Linear(d_model, d_model)
self.value = nn.Linear(d_model, d_model)
def forward(self, modality_a, modality_b):
# Q, K, V for cross-modality interaction
Q = self.query(modality_a)
K = self.key(modality_b)
V = self.value(modality_b)
# Attention computation
attention_weights = F.softmax(torch.matmul(Q, K.transpose(-2, -1)) / (Q.size(-1)**0.5), dim=-1)
cross_modal_output = torch.matmul(attention_weights, V)
return cross_modal_output
# Example: Text attending to Video features
cross_modal_attention = CrossModalAttention(d_model=512)
cross_modal_output = cross_modal_attention(text_encoded, visual_features)
In this example, we make text attend to video features, enabling the model to understand the connection between the text and corresponding visual actions, even if they aren’t perfectly aligned.
4. Multimodal Fusion Layer
Once cross-modal attention has been applied, the outputs from all modalities are combined into a unified representation. This fusion layer can be as simple as concatenation or more complex, using learned fusion techniques (e.g., weighted averaging or attention fusion). Here’s an example of multimodal fusion using concatenation:
class FusionLayer(nn.Module):
def __init__(self, d_model):
super(FusionLayer, self).__init__()
self.fc = nn.Linear(d_model * 3, d_model)
def forward(self, text_features, audio_features, visual_features):
combined_features = torch.cat([text_features, audio_features, visual_features], dim=-1)
fused_output = self.fc(combined_features)
return fused_output
# Fusion of text, audio, and video
fusion_layer = FusionLayer(d_model=512)
fused_representation = fusion_layer(text_encoded, audio_features, visual_features)
In the example above, the output of each modality is concatenated, passed through a linear layer, and used to predict the final outcome (e.g., classification).
5. Final Prediction
The final step involves predicting the output (e.g., classification, sentiment score, action detection) from the fused multimodal representation. A fully connected layer (or layers) is applied to produce the final output.
class PredictionHead(nn.Module):
def __init__(self, d_model, num_classes):
super(PredictionHead, self).__init__()
self.fc = nn.Linear(d_model, num_classes)
def forward(self, fused_representation):
return self.fc(fused_representation)
# Example: Sentiment Classification
num_classes = 2
prediction_head = PredictionHead(d_model=512, num_classes=num_classes)
final_output = prediction_head(fused_representation)
Training the Multimodal Transformer
The model is trained end-to-end using a contrastive loss that pushes similar representations of different modalities closer and dissimilar ones apart. The cross-modal contrastive loss helps in learning better interactions across asynchronous modalities. Here’s a brief code snippet to demonstrate how contrastive loss could be implemented:
class ContrastiveLoss(nn.Module):
def __init__(self, margin=1.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
distance = F.pairwise_distance(output1, output2)
loss = (label * torch.pow(distance, 2) +
(1 - label) * torch.pow(torch.clamp(self.margin - distance, min=0.0), 2))
return loss.mean()
# Example: Compute contrastive loss between audio and visual representations
contrastive_loss = ContrastiveLoss()
loss = contrastive_loss(audio_features, visual_features, label)
This loss function helps the model learn meaningful relationships across modalities and improves its ability to generalize to unaligned sequences.
Conclusion
The Multimodal Transformer for Unaligned Multimodal Language Sequences tackles a challenging problem in machine learning: integrating asynchronous and unaligned data from multiple modalities. By leveraging a combination of self-attention, cross-modal attention, and contrastive learning, this model successfully captures dependencies between different modalities, even when they’re not perfectly synchronized. The architecture, consisting of modality-specific transformers, cross-modal attention, and fusion layers, is both elegant and powerful, making it applicable across various tasks involving complex multimodal data. ***
References
Enjoy Reading This Article?
Here are some more articles you might like to read next: